The limitations of data
My current research on Gender in Computer Science in the twentieth Century can be seen as an extension, or better, a prelude, to my research on the gender balance in computer science conferences and the digital humanities conference between 2000 and 2015 during my Master of Digital Humanities at KU Leuven. In my dissertation I mainly studied the links between co-authors who collaborated on conference papers. In order to study the gender balance and connections between co-authors for the computer science conferences, I used a dataset created by Agarwal et al. in 2016 which is available on Mendeley.1
The promised land of bibliographic data
Bibliographies aid researchers in browsing through collections of books, articles, journals and proceedings. Before the advent of the digital age, these massive volumes of titles and authors per research field, country or language mostly served researchers and librarians. When these collections were transformed into online databases, the bibliography suddenly offered insights into academia when processed correctly. Apart from the author and title, entries also contain venue or publisher, and the type and year of publication. Furthermore, online versions sometimes provide full-text and bibliometrics in addition to abstracts and tables of content. Several tools gratefully employ this data to uncover research area evolutions and communities that show current trends in scientific inquiry, as well as academic social networks in the form of undirected collaboration networks or directed dispute networks2. The conference data obtained from bibliographic databases contain authorship demographics which allow a general comparison of different conferences, including factors such as age, authorship position, career position, gender and affiliation. Furthermore, this data also provides the basis for the creation of co-authorship networks.
Since online bibliographic data offers a lot of information on co-authorship and citations, it can provide invaluable insights into academia. The creators of the dataset I used concluded in Women in Computer Science Research that research participation and collaboration of female authors increased by less than 0.1% per year between 2000 and 2015, and male researchers represent 79% of actively publishing members in computer science conferences. The dataset which formed the foundation of this research is derived from a snapshot of the DBLP bibliography database in September 2015.3 The “Data Bases and Logic Programming” (DBLP) Digital Library started as a formatted HTML collection of Tables of Contents created by Michael Ley for his PhD.4 Research has shown biases in the DBLP bibliography in the coverage of computer science since it promotes conferences on Databases, Information Retrieval, Digital Libraries and Data Mining, and on Programming Languages.5
- 1.
Swati Agarwal, Ashish Sureka, Nitish Mittal, Rohan Katyal, Denzil Correa, “DBLP Records and Entries for Key Computer Science Conferences”, Mendeley Data, version 1, doi: http://dx.doi.org/10.17632/3p9w84t5mr.1.
- 2. Meng Qi Yelena Wu, Robert Faris, Kwan-Liu Ma, “Visual exploration of academic career paths,” ASONAM 13 Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, 779-786. doi: http://dl.acm.org/citation.cfm?doid=2492517.2492638.
- 3. Agarwal et Al., “DBLP Records and Entries”.
- 4. Florian Reitz and Oliver Hoffman, “An Analysis of the Evolving Coverage of Computer Science Sub-fields in the DBLP Digital Library,” (2010) In: Lalmas Michael Ley, The DBLP Computer Science Bibliography: Evolution, Research Issues, Perspective
- 5. Florian Reitz and Oliver Hoffman, “An Analysis of the Evolving Coverage of Computer Science Sub-fields in the DBLP Digital Library,” (2010) In: Lalmas M., Jose J., Rauber A., Sebastiani F., Frommholz I. (eds) Research and Advanced Technology for Digital Libraries. ECDL 2010. Lecture Notes in Computer Science, vol 6273. Springer, Berlin, Heidelberg, doi: http://link.springer.com/chapter/10.1007%2F978-3-642-15464-5_23.
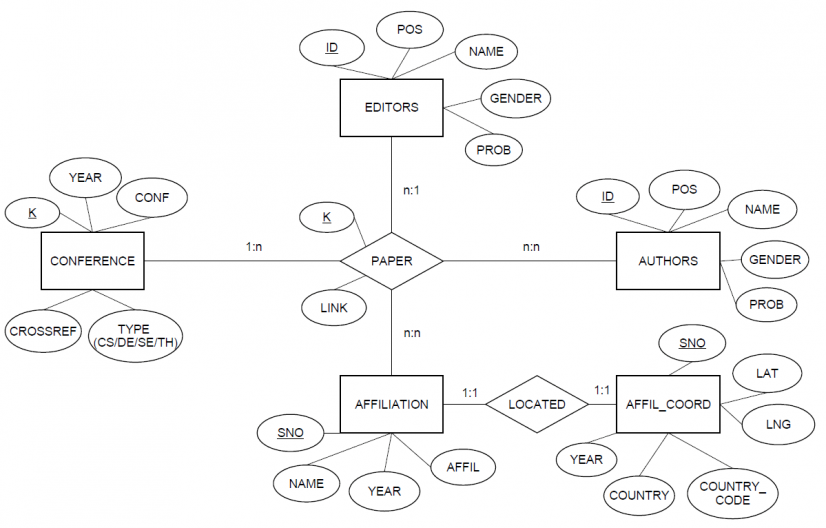
Because the links between tables in the dataset based on the DBLP Digital Library were quite unclear, I created this Entity Relationship – diagram. This ER-diagram does not show all tables in the dataset, but focusses on the tables I needed for my research. The type of conference refers to the classification of Agarwal et al. into four distinct sub-fields, namely Software Engineering (SE), Data Engineering (DE), and Theory (TH), as well as Computer Science (CS) in general. In order to create an overview in the form of several visualisations, I performed several queries. One example illustrated below joins the name of an author (au.name), the conference he/she attended (g.conf) and the specific paper (g.k) to link authors together. In order to add useful colour coding and filters, I added gender (au.gender), position (au.pos) and year (g.year). The SQL-query for two specific conferences looked like this:
SELECT g.k, g.year, g.conf, g.link, au.id, au.name, au.pos, au.gender, au.prob
FROM general g
INNER JOIN authors au ON g.k = au.k
WHERE g.year >= 2000 AND (g.conf = ‘CHI’ OR g.conf = ‘UIST’)
Although I want to refer to the term gender as the psychological and sociological gender a person identifies with (according to the definition of the Oxford English Dictionary), the data conflicted with this definition. Gender in this dataset was assigned based on the genderize API (Application Programming Interface) which calculates the probability of a first name being male or female, and thus adheres to the binary form of gender, being either male or female. The creators did not determine the gender of an author when he/she only had initials, or when the probability or confidence score of the genderize API was below 60%. Out of a total of 416 445 authors, 14,2% could not be determined in terms of gender, while 69,1% were identified as male and only 16,7% were identified as female. Furthermore, the API does not take into account the country of origin, and thus identifies Italian authors named Andrea as female, whereas in Italy the name is used for men rather than women.
Asking impossible questions
There are however limitations to this rich information:
- You can check for collaboration by linking co-authors, but you can’t understand their experience in collaborating by only checking their names.
- You can see whether both authors were linked to the same affiliation, but you cannot know whether they share an office, or whether they are actually located at the same campus (unless you add that information manually or semi-automated).
- You cannot detect from this dataset who informally already knows each other, and how connected they are in real life or on social media. That is not only an issue of privacy, but also the problem of access to data. Perhaps the large companies gathering the data have access, but often they are only interested in the commercial value of the data and less interested in the value this data might have for sociological studies.
- You can assign gender based on a dataset of identified first names, but other than the probability index of the genderize api dataset there is no way of checking whether this aligns with the individual’s personal vision of their gender.
Furthermore, the binary opposition between men and women perfectly suits the need for precision required by computers/in the dataset, but obscures the entire gender debate whereby gender is a social construct and does not necessarily align with someone’s sex. Classifying people into rigid categories also leaves no room for changes over time.
Therefore, a relational dataset may offer some preliminary insights but these insights need to be compared to the reality of academics collaborating, and to the perception of the importance of certain authors who seemingly contributed more solely based on their perceived gender or their position in the list of names. Let’s avoid the one-sentence #thanksfortyping where professors thank their wife for typing (and thus performing) most of the work, disregarding the true contribution of some members of the team.

