TIM is a tool for indexing and annotation of interview recordings. We are releasing a prototype version and wanted to let you know about it. If you would like to test it, build it into a project, or just be kept informed of our progress, please email us: douglas.lambert@uni.lu or zack@theirstory.io.
What does TIM do?
Indexing at the timecode level is a practice increasingly embraced for accessing oral histories in synchronized multimedia display systems, like OHMS and Aviary. TIM takes a new approach to building an index, using a free-form editing environment for text, combined with flexible tools for establishing timecodes. Whether for online publication, research, or both, an index can be built without any preset structures and with whatever text resources are available (e.g., existing notes, annotations, or transcripts--even imperfect ones.)
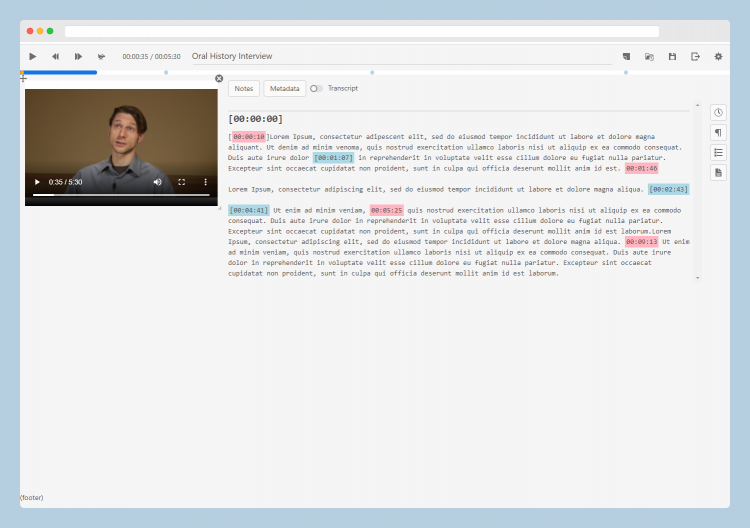
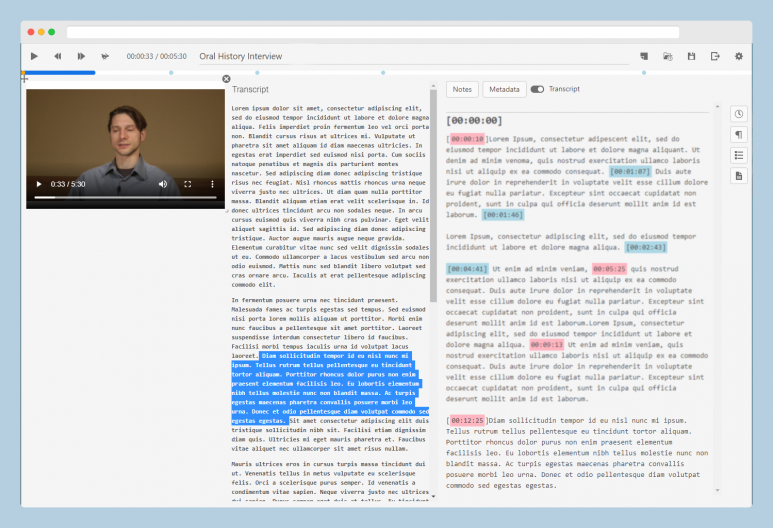
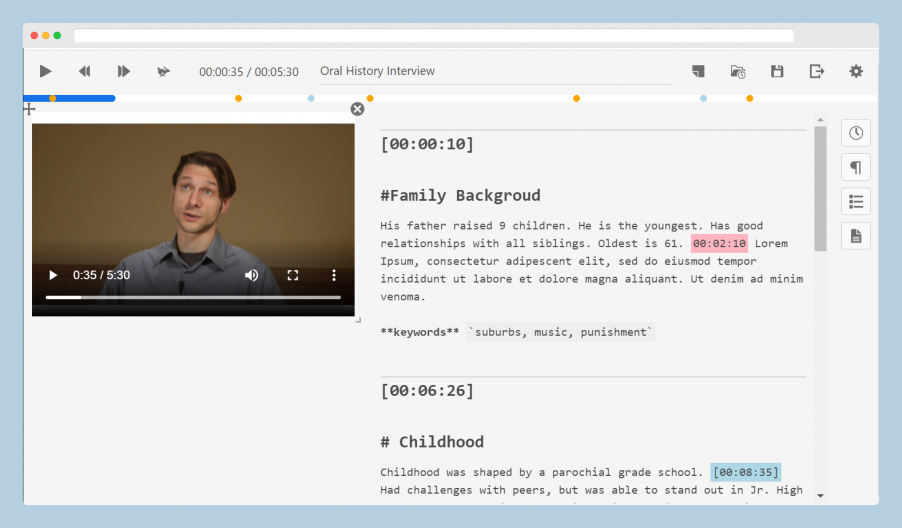
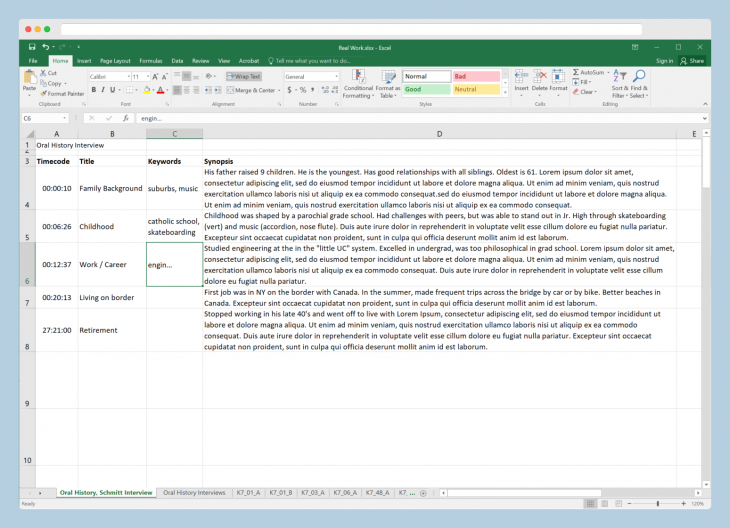
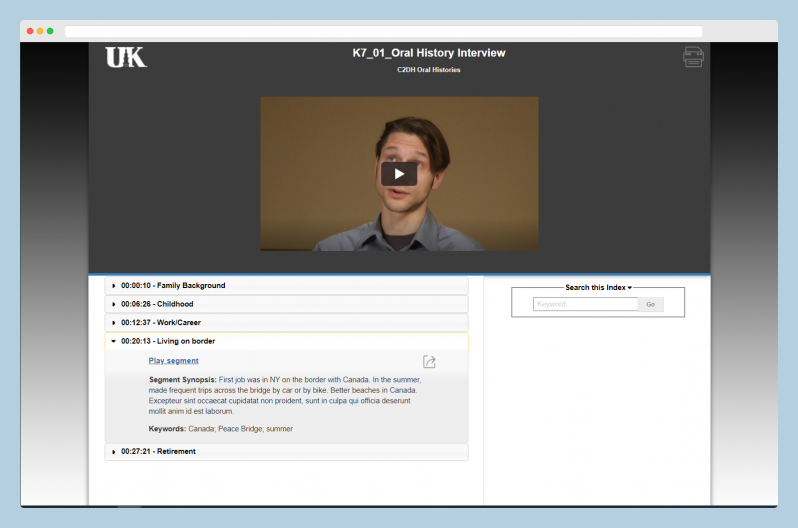
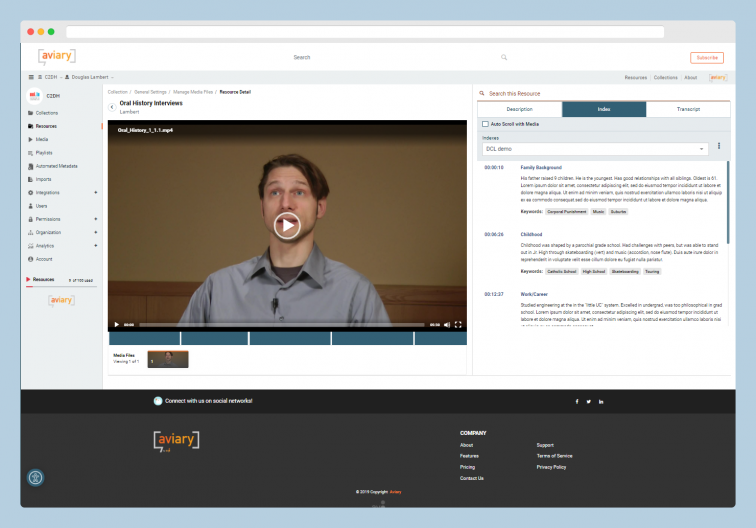
TIM allows users to form structured metadata using either markdown code in the text or through a visual interface. The metadata can be exported in several open formats for long-term display in publishing environments (OHMS/Aviary), or to other environments for additional content processing, analysis, or research work. The first phase of the TIM project has been sponsored by the C²DH at the University of Luxembourg. The project is led by Douglas Lambert, in partnership with Zack Ellis (TheirStory) and supported by the C²DH’s Digital Research Infrastructure team. Support via a Thinkering Award from Andreas Fickers and the C²DH management team made this work possible.
To be a partner in the next phase of TIM, contact Doug Lambert at douglas.lambert@uni.lu or bert@buffalo.edu.

