
The University of Luxembourg’s Master in Contemporary European History not only intends to train the future historians, but to train a new generation of historians who will work with fundamentally different sources and resources than their predecessors. It is in this spirit that the University offered in 2016 a winter school in digital history to the students in the first year of their master’s degree in history, an initiative renewed on an annual basis.
In 2016, I was myself enrolled as a student in the Master and, while the experience of the winter school was highly interesting, it was also exhausting. In fact, approaching digital history demands not only training the students but also training the trainers. When the winter school was first organized, the schedule was dense and tried to cover every single topic related to the upcoming field, from the digitization process to big data analysis, digital source criticism and possible tools to create virtual exhibitions. Within five days, we students faced seven different lecturers and five different topics, a configuration that left us with the definite understanding of how complex digital history is, but without giving us the chance to really grasp the impacts of this complexity.
In 2018, the Luxembourg Centre for Contemporary and Digital History (C²DH), the University’s youngest interdisciplinary research centre, held the third edition of the winter school in digital history and the organizers Anita Lucchesi and Max Kemman kindly allowed me to participate in its elaboration. Taking on the teaching perspective of the project, I can now understand the struggle that comes from bringing together a scientific and critical approach to digital history and students who are familiar with digital methods to an extent that they don’t review them critically anymore. As Marshal McLuhan puts it: Web based research was, at its beginnings, so innovative that it was prominent in the users’ mind. It was “figure” to their approach of the internet. Today, the new media have become so inherent to students’ daily life that no thought is being given to their functioning; they become “ground” to web-based research processes.1
Creating a digital archival collection from scratch
Despite this complicated starting point, the aim to train the trainers proved to be successful over the last three years. Instead of trying to fit every single aspect there is to know about digital history and its wide ramifications into one week, this year’s winter school focused on one single aspect, which is the creation of a digital archival collection from scratch. We therefore offered theoretical and hands on reflections on the digitization process, on web publishing platforms to create and manage digital collections (in particular OMEKA), as well as on the perils and promises that come along with this new form of primary source management. During the whole week, students also worked with a predefined sample of primary sources from the historical archive of the Luxembourgish Postal Service. In fact, every group among the three we formed, was given four different types of postal sources. First of all, they worked with files related to a single postal office in the Grand-Duchy. These files mostly covered the period from the 1880s to the 1950s. Additionally, a second file with photographs and negatives of the same postal office but from a different time period (1970s – 1990s) was integrated into the corpus. The sample was completed by one file retracing a particular stamp’s entire creation process, from the first idea to the final product, and several annual reports of the administration, respectively the enterprise.
Before starting the digitization of this sample, we asked the students to comment on digital archival collections. As expected, they insisted on the advantages such as permanent or at least simplified access to the sources as well as benefits and search efficiency resulting from OCR (Optical Character Recognition). They however also proved to be aware of challenges in the digitization process of existing archives, pointing out difficulties in terms of funding, sustainability and reliability of the created collections, as well as the necessity to train historians to new forms of research. The students also identified perils: Funding issues can lead to selective digitization and raise the question of who defines the selection criteria as well as how to deal with the resulting bias. Similarly, the handling of digital born sources also implies facing the problem of selection. In this case, the limitations lie within the storage and not the digitization itself, showing one of the issues of the “age of abundance” as defined by Roy Rosenzweig.2 Not only since Donald Trump claimed twitter as his favorite communication tool, tweets have become an important primary source for research on various topics. This is why, in 2010, the Library of Congress decided to preserve and store every single public tweet. However, in December 2017, the institution had to abandon this project due to the overwhelming increase in the number of tweets and the storage capacities they required within the library network. Since 2018, only selected tweets are preserved, while the discretion criteria applied by the library’s archivists remain widely unknown.3
Finally, the students also emphasized the lack of homogenous guidelines, protocols and standards to be followed by digitization projects, creating an almost chaotic research situation.
Interestingly, once the class started to digitize their samples, more practical questions and reflections were raised. What resolution should the scans be saved in, in order to find a balance between the high quality needed to assure that the sources could be used in virtual exhibitions or other publishing formats and the time consumed by the process? What format should the files be saved in to guarantee easy access and high quality? How should metadata be registered and to what extent has this register to be precise?
Simultaneously, the groups were asked to not only digitize their documents, but to reflect on the target public for their collection and the organization system of the data that was needed in consequence. It was fascinating to see that the three groups formed at the beginning of the week established three completely different approaches to the task. This diversity was also mirrored by the schemes the groups were asked to prepare in order to illustrate the process from the analogue to the digital source.
Group 1: Creating a category-based storage system
One group first focused on the file with documents related to the postal office of Mersch. Instead of assembling all the documents in one block, they decided to divide them into categories relating to their content. Considering an overall subject of administration, they divided the documents, mainly letters and service orders, into three categories (Postal service, telecommunication service, financial service). This categorization was based on a previous introduction to the archive as well as close reading and demands for further information from the lecturers. The group established this modus operandi before even starting the digitization process and only reflected on the metadata they needed to collect when they actually started to scan.
- 1. MCLUHAN M., POWERS B., The Global Village: Transformations in in world Life and Media in the 21st Century, Oxford, Oxford University Press, 1989. ; For a broader development of McLuhans concepts in the context of web based media see : ISBOUTS J.-P., OHLER J., “Storytelling and media: Narrative models from Aristotle to Augmented Reality”, in DILL K. E. (ed.), The Oxford handbook of media psychology, Oxford, Oxford University Press, 2013, p. 13-42. Especially pages 29 to 36.
- 2. ROSENZWEIG R., “Scarcity or Abundance? Preserving the Past in a Digital Era”, in The American Historical Review, vol. 108 / n° 3 (2003), p. 735-762.
- 3. NEW YORK TIMES, CHOKSHI N., The Library of Congress No Longer Wants All the Tweets, [Online], https://www.nytimes.com/2017/12/27/technology/library-congress-tweets.html. (Page consulted : 19.02.2018 ; Last updated : 27.12.2017)
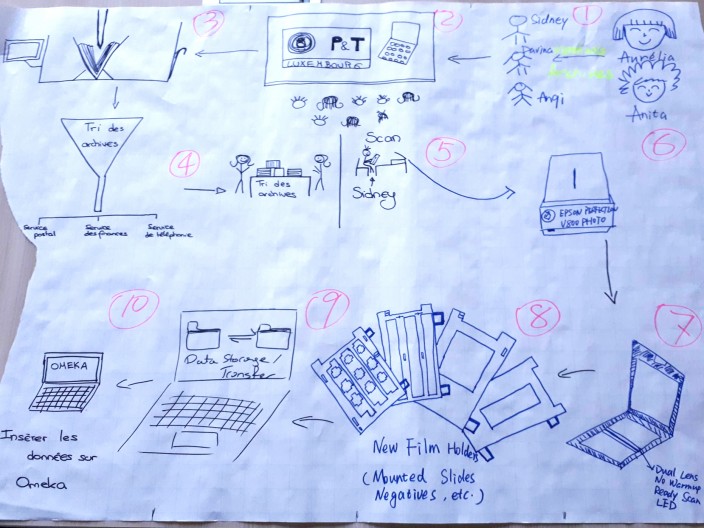
The scheme this first group draw of the scanning process consequently Insists on the necessity to reflect on the archives before starting the scanning. On the contrary, their scheme doesn’t try to explain the black box the scanner represents. It is considered a given tool and apparently, as long as it functions normally, no explanation is needed.
Group 2: Scanning first, categorizing second
A second group started to work with the file about the post stamps, namely a stamp celebrating Luxembourg’s hosting of the North Atlantic Council in 1967.
Unlike the first group, these students decided to first create an Excel-table with the relevant metadata categories and collected them while scanning the documents. The theoretical table was adapted to the reality of the documents while the scanning progressed and only after the digitization process was complete, they reflected on a possible categorization and presentation of the material.
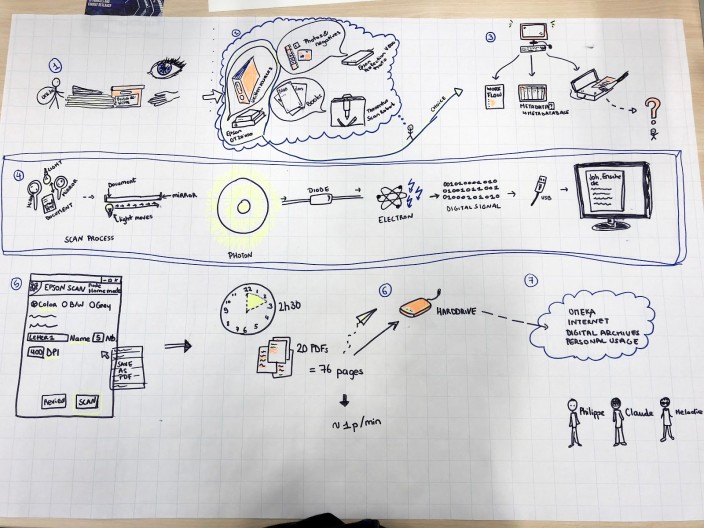
In their scheme, this second group also insisted on the thinking process that was needed before the beginning of the digitization, but they also tried to solve the black box that the scanning device represents.
In the collective discussion, one member of this group stated that before starting the project, she thought that digitizing would just imply placing a document into the scanner and pushing a button. However, the student soon realized that the digitization process was much more complex and time consuming than expected. Needless to say, that we appreciated this comment as an important learning outcome.
Group 3: Learning from others’ mistakes
The third and final group followed a different path than the previous ones due to the fact that they started their digitization process on the TREVENTUS book scanner and thus needed in-depth training provided by Andy O’Dwyer. Since the use of the book scanner imposes a preset method to encode metadata, this group didn’t reflect on collecting this type of information nor how to make sense of their sample on the first day of the winter school.
Their scheme consequently reflects the functioning of the book scanner more than the complete digitization process.

Having heard the reports of their classmates about the difficulties they encountered when starting their respective project, the third group adapted their work flow in a way to avoid these same issues.
In conclusion, I would consider the third edition of the winter school in digital history a success. Training the trainers while training the students proved to be an efficient way to improve the learning outcomes of the sessions and I can clearly state that this year’s winter school was far more useful for the attending students than the first edition in 2016. Nevertheless, the process is not yet completed and I am convinced that the hands-on method will help to even further improve the model of the winter school in the following years. And this evolution is highly important, because the new media are here to stay and already are and necessarily will influence the way historians do research. It is up to us to prepare these present and future.
