
Avec l’apparition du COVID-19 et sa diffusion dans le monde et bien que n’étant pas historien de la médecine ou des sciences, l’historien de l’entre-deux-guerres que je suis a immédiatement pensé à la fameuse grippe espagnole, qui a causé en 1918 et 1919 de 50 à 100 millions de morts, soit une mortalité équivalente à celle de la Seconde Guerre mondiale. Nos collègues médiévistes évoqueront aussi la peste noire du XIVe siècle qui, en cinq ans, a possiblement tué la moitié de la population du continent européen1.
La perspective historique ne doit pas toutefois nous empêcher de voir les éléments nouveaux de la crise que nous vivons. 2,4 milliards d’humains sont aujourd’hui confinés à des degrés divers, soit un tiers de la population mondiale estimée. Une grande partie de la population confinée est, par ailleurs, connectée
Notre monde de données rend ainsi la pandémie du COVID-19 exceptionnelle par la perception commune à une grande partie de l’humanité et en temps réel de son développement. Cette pandémie « connectée » pose une question, dès maintenant, particulièrement importante: celle de l’archivage de ses traces et celle de la préservation de sa mémoire.
De nombreuses initiatives sont en cours à l’heure actuelle2. Au C²DH, plusieurs d’entre nous ont commencé des projets pour préserver la mémoire de la pandémie au Luxembourg et ailleurs. Ces initiatives feront l’objet d’une présentation plus complète dans les jours et les semaines à venir sur le site web #covidmemory.
Nous avons notamment, le dimanche 15 mars à partir de 9h, lancé une collecte de tweets.
Une pandémie sur Twitter
Pourquoi collecter des tweets
Les tweets sont des traces – ce que les historiens et historiennes appellent des sources primaires – que notre présent laisse pour une compréhension future de ce qui devient passé. Les tweets que nous collectons sont ainsi des traces de la crise en cours, traces qui, parmi d’autres, nous permettront de comprendre cette pandémie, de comprendre comment des Européens ont vécu ces mesures exceptionnelles de confinement.
Collecter ces tweets est une manière d’observer l’histoire en train de se faire, mais aussi de comprendre comment la mémoire de cet événement est en train de se structurer. Nous devrions dire plutôt « les » mémoires : un premier aperçu des hashtags (voir ci-dessous) montre à quel point les réactions aux mesures prises, à la crise peuvent varier.
Par un mode de médiation très spécifique, mettant (au moins théoriquement) en lien direct citoyens, journalistes, institutions, etc, Twitter permet d’observer beaucoup d’éléments de nos vies quotidiennes, politiques, culturelles, économiques, sociales qui étaient plus difficiles à saisir auparavant. Twitter favorise également la diffusion d’informations à grande vitesse, à haute fréquence3. Twitter est, ainsi, une plateforme paradigmatique de notre temps, de sa constante quête de mise à jour, d’actualité, de vie en direct. Et c’est bien l’interaction entre ce présent se mettant à jour en permanence4 sur Twitter et la portée historique de cette pandémie qui aboutit à cette construction en direct des mémoires de ce même événement. La confrontation des temporalités – celle de Twitter, celles des utilisateurs, celle de l’événement, celle de l’historien, celle de la mémoire – rend Twitter déterminant pour comprendre notre monde.
Conditions de la collecte
Nous avons lancé la collecte dimanche 15 mars matin. Elle est limitée à des hashtags français et francophones pour des raisons techniques5. En effet, collecter un mot-clé comme #covid19 aurait engendré un dépassement des conditions de collecte de tweets : Twitter limite le nombre de tweets collecté gratuitement à 1% des tweets globalement émis sur sa plateforme. Comme environ un demi-milliard de ces petits messages sont publiés quotidiennement, nous pouvons ainsi en collecter théoriquement jusqu’à 5 millions par jour environ. Cette limite est cependant calculée sur 15 minutes et non sur la journée: même en limitant notre collecte à des hashtags francophones, nous l’atteignons une à deux fois par jour6.
Descriptif de la base de données au 24 mars
La base de données ainsi amassée représentait le 24 mars à 23:59 un peu moins de huit millions de tweets pour 1,5 millions environ d’utilisateurs. La figure 1 donne un aperçu statistique de la base de données. 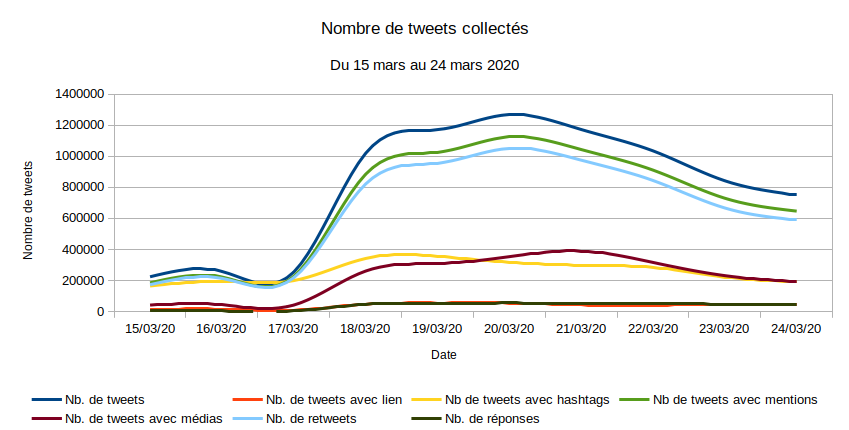
Figure 1 - Nombre de tweets collectés
Mémoire collective et protection des données
Une déclaration a été faite auprès du Data Protection Officer (DPO) de l’Université du Luxembourg. Vous trouverez une page sur le site web du C²DH donnant quelques informations sur la collecte et le traitement de ces données.
Au-delà de la conformité (très importante) de cette collecte avec le RGPD, au-delà du respect des droits de chacun envers ses données personnelles, se pose la question de la relation entre ce respect et la recherche sur la mémoire de cet événement. Pour encourager cette recherche – et ce n’est pas le seul cas où cette question se pose –, il sera important de pouvoir mettre à disposition, sous une forme ou sous une autre, vraisemblablement de manière anonymisée (ce qui n’est pas toujours réalisable pour différentes raisons), ce jeu de données à d’autres chercheurs et chercheuses, car il permet de poser de nombreuses questions de recherche, y compris des questions dont nous n’avons pas encore idée. Toutefois, les conditions de cette mise à disposition sont encore incertaines.
D’autres jeux de données Twitter
Notre base de données pourra être croisée et complétée avec d’autres jeux de données. Par exemple, un corpus a été déposé sur le dataverse de Harvard contenant plus de 51 millions d’identifiants de tweets7. Seuls les identifiants de tweets sont disponibles, mais ils peuvent ensuite être réhydratés si, du moins, ils n’ont pas été supprimés par leur auteur.
Limites de ces jeux de données
Les bases de données de tweets sont toujours impressionnantes par leur masse. Mais leur volume ne signifie pas pour autant intégralité des données, même s’il peut en donner l’impression. Ian Milligan parle d’ordre illusoire8.
Aller sur Twitter permet de comprendre à quel point ces huit millions de tweets collectés ne sont qu’une partie des tweets et des conversations en français autour du COVID-19. De nombreux tweets n’ont aucun des hashtags collectés ici. De plus, un tweet stocké dans notre base de données peut donner lieu à une discussion qui ne reprendra pas ou qu’en partie la discussion qui a eu lieu sur Twitter, car certains tweets de la conversation ne reprennent pas les hashtags collectés9.
Nous ne sommes donc pas sur un corpus que l’on peut considérer comme représentatif, ce qui ne veut pas dire que l’on ne puisse rien en faire. L’étape de la généralisation est simplement plus ardue. Par ailleurs, les liens entre ce qu’il se passe sur Twitter et ce qui se dit d’une part, avec les autres médias sociaux comme Facebook, Whatsapp ou Snapchat et d’autre part «off line» (si jamais mondes off- et on-line peuvent aujourd’hui être séparés) sont flous, difficiles à interpréter.
De plus, la collecte est dépendante de l’interface de programmation que Twitter met à disposition. Nous utilisons l’API dite de streaming. Elle est limitée à 1% du flux des tweets, comme nous l’avons déjà précisé, et ne permet pas de fouiller l’historique des tweets émis. Il est possible de collecter des données dans l’historique de Twitter, mais de manière très limitée (environ 3000 tweets par heure remontant à sept jours). Cela signifie que nous devons anticiper les hashtags qui seront les plus utilisés à l’avenir (même proche), ce qui implique une veille de tous les instants10.
Quelques analyses préliminaires
Les analyses que nous allons ici exposer sont les premières que nous ayons faites, plus pour avoir une idée de la morphologie et du contenu de la base de données qu’à des fins, pour le moment, de recherche. Le but de cette base de données est en premier lieu de garder des traces de la mémoire collective de l’événement que nous vivons pour des analyses futures.
La base de données dans le temps
La figure 2 nous permet un aperçu rapide de l’évolution de la base de données depuis le 15 mars, en montrant la proportion des vingt hashtags les plus utilisés (essentiellement ceux qui sont collectés) dans notre base de données.

Figure 2 - proportion des vingt hashtags les plus utilisés dans notre bae de données, du 15 au 24 mars
Cette figure ne recèle pas de grandes surprises. À partir de l’annonce du confinement en France (le 15 mars au soir, lors du discours d’Emmanuel Macron11), les hashtags liés au confinement (#confinement, #confinementjour2 et suivants) prennent le pas sur des hashtags que nous avons collectés comme #electionsmunicipales2020 car ils sont devenus un enjeu du débat autour du COVID-19 en France. Bien entendu, les hashtags faisant référence à un jour précis (#confinementjour2 et suivants – #confinementjour1 a été collecté trop tardivement pour apparaître ici) apparaissent plus particulièrement les jours qu’ils évoquent (le 18 mars pour #confinementjour2 par exemple). On aperçoit néanmoins une traîne, liée aux retweets, les jours suivants, des messages contenant ces hashtags. Il faudra tenter d’interpréter le fait que certains mots-dièse relevant de la vie quotidienne pendant le confinement prennent le pas sur des hashtags (covid19fr par exemple) liés à la maladie elle-même.
Les grands thèmes
En pratiquant une lecture à distance du corpus – c’est-à-dire en demandant à l’ordinateur de lire pour nous – non pas 8 millions de tweets mais les un peu moins de 1,4 millions de tweets originaux (le corpus sans les retweets), nous pouvons déduire quelques grands thèmes évoqués dans les tweets. Il s’agit, pour le moment, d’une lecture très peu en profondeur dont la fonction est d’avoir une idée globale du contenu de notre base de données.
 de notre base de données")
Figure 3 – Classification hiérarchique descendante des tweets (sans retweet) de notre base de données
Dans ces différents profils de tweets dont les mots les plus représentatifs sont exposés, nous pouvons voir des éléments sur les municipales françaises (classe 2) avec du vocabulaire classique des élections, mais également des éléments liés à l’épidémie (jeniraipasvoter), des classes consacrées au confinement et à la nécessité de le respecter (classe 5), de nombreuses classes sur les activités pendant le confinement (classe 6, classe 9, classe 7), le ras le bol du confinement (classes 8 et 4, cette dernière étant un peu plus ambiguë), une classe qui regroupe des tweets en anglais qu’il faudra éventuellement analyser séparemment (classe 1) et la classe 3 qui rassemble probablement des tweets cumulant de nombreux hashtags (une pratique courante, parfois pour se faire remarquer).
Projection dans le temps
Ces profils de tweets peuvent être projetés dans le temps, afin de voir leur évolution au fil des jours du confinement.

Figure 4 – Évolution chronologique des profils de la figure 3
La figure 4 montre l’évolution des grands thèmes dégagés par l’analyse du contenu des tweets de notre base de données. Si dans un premier temps, les thèmes liés aux municipales sont les plus pertinents, ce sont ensuite, notamment à partir du 18 mars (au moment où le hashtag #confinementjour2 est utilisé, alors que nous n’avons pas inclut suffisamment tôt #confinementjour1), les thèmes liés au confinement qui dominent dans notre base de données.
Conclusion et pistes de recherche
Ce premier aperçu des tweets que nous collectons est sommaire et parle plus de la base de données et des choix de collecte que nous avons faits que du confinement et de l’épidémie tels qu’ils ont été vécus. Ce sont les recherches futures qui permettront de préciser les conditions dans lesquelles cette base de données servira à comprendre comment cette période de confinement a été vécue. L’urgence aujourd’hui est de travailler à préserver la mémoire et les archives nées numériques de cet épisode. Nous espérons ainsi que les recherches qui se fonderont sur cette base de données et sur d’autres efforts entamés au C²DH comme ailleurs permettront de mieux comprendre ce que nous vivons aujourd’hui.
- 1. Vous pourrez consulter plusieurs articles de l’encyclopédie pour une histoire nouvelle de l’Europe pour approfondir: « Risques et sécurité » d’Alain Beltran, « Les épidémies et les quarantaines en Europe » de Celia Miralles Buil. Certain·e·s collègues ont déjà publié des billets faisant le parallèle entre certaines épidémies historiques et la crise que nous vivons. Par exemple: « Plague in the Age of Twitter » d’Eileen Sperry (17 mars 2020, sur le blog collectif Nursing Clio.
- 2. Par exemple, en Allemagne, coronarchiv. En France: le carnet de recherche Confinements.
- 3. Voir les travaux de Dominique Boullier: Boullier, Dominique. 2015. « Les sciences sociales face aux traces du big data ». Revue française de science politique 65 (5) : 805–828.
- 4. Silva, Matheus Henrique Pereira da et Valdei Lopes de Araujo. 2017. « Actualismo y presente amplio: breve análisis de las temporalidades contemporáneas ». Desacatos: Revista de Ciencias Sociales, no 55 : 12-27.
- 5. Les hashtags sont des mots précédés d’un croisillon, dont la fonction est multiple et ambivalente, mal traduit en français par mot-dièse. Les hashtags collectés sont: SolidariteCOVID19, confinementjour10, confinementjour9, coronamaison, confinementjour8, confinementjour7, confinementjour6, bibliosolidaire, biblisolidaire, confinementjour5, confinementjour4, confinementjour3, confinementjour2, confinementjour1, confinement, CORONAVIRUSENFRANCE, RESTEZCHEZVOUS, onvousrepond, culturecheznous, CoronavirusFr, COVID19france, municipales2020, CoronavirusFrance, jeniraipasvoter, restecheztoi, covid19fr. Nous les collectons sans le croisillon, afin d’élargir un peu la collecte.
- 6. Le dispositif technique mis en place est le suivant: nous utilisons le logiciel de collecte et d’analyse de tweets DMI-TCAT (E. Borra and B. Rieder (2014) “Programmed method: developing a toolset for capturing and analyzing tweets,” Aslib Journal of Information Management, Vol. 66 Iss: 3, pp.262 - 278. http://dx.doi.org/10.1108/AJIM-09-2013-0094).
- 7. Twitter n’autorise que le partage des seuls identifiants des tweets. Ils doivent ensuite être «réhydratés» par des outils comme twarc, par exemple.
- 8. Milligan, Ian. 2013. « Illusionary Order: Online Databases, Optical Character Recognition, and Canadian History, 1997–2010 ». Canadian Historical Review 94 (4) : 540-569. https://doi.org/10.3138/chr.694.
- 9. D’heer, Evelien, Baptist Vandersmissen, Wesley De Neve, Pieter Verdegem et Rik Van de Walle. 2017. « What Are We Missing? An Empirical Exploration in the Structural Biases of Hashtag-Based Sampling on Twitter ». First Monday 22 (2). http://firstmonday.org/ojs/index.php/fm/article/view/6353.
- 10. Nous utilisons des outils gratuits comme talkwalker pour tester régulièrement les hashtags que nous collectons.
- 11. Chaque discours d’Emmanuel Macron donne lieu, logiquement, à un pic de publication de tweets.
