Using text mining and data visualisation to open up collections of digitised historical newspapers for research.
Since its launch in 2017, impresso has developed a methodologically-reflected technological framework to enable new ways of engaging with the multilingual digital content of historical newspapers and new approaches to address historical questions. impresso is a joint project run by the C²DH, the DHLAB at the École polytechnique fédérale de Lausanne (EPFL) and the Institute of Computational Linguistics at the University of Zurich. Content is provided by a number of partner institutions including the National Library of Luxembourg, the Swiss National Library, Le Temps and the Neue Zürcher Zeitung.
Animated video presentation of the impresso projectThe project has three main areas of focus, reflecting the combined research interests of the participating institutions:
- the application of text mining techniques to transform unstructured, large-scale and noisy textual content into semantically indexed, structured and linked data;
- the co-design and implementation of an innovative visualisation interface to enable the seamless exploration of vast amounts of complex historical data; and
- the effective use of these new tools and methods, whose strengths and weaknesses are best evaluated when challenged by scholars working on historical research questions.
After a first period laying the basis for the data and identifying user requirements, 2019 saw the materialisation of the early designs and projections. The Swiss and Luxembourgish newspaper collection grew significantly, despite initial difficulties with the diversity of digitisation formats. One of the goals of the project is to overcome the silos of digitised newspapers stored in various (national) collections. The next step was to process all the newspapers through the same natural language processing pipeline, so that researchers could interrogate the whole transnational and multilingual collection from one interface.

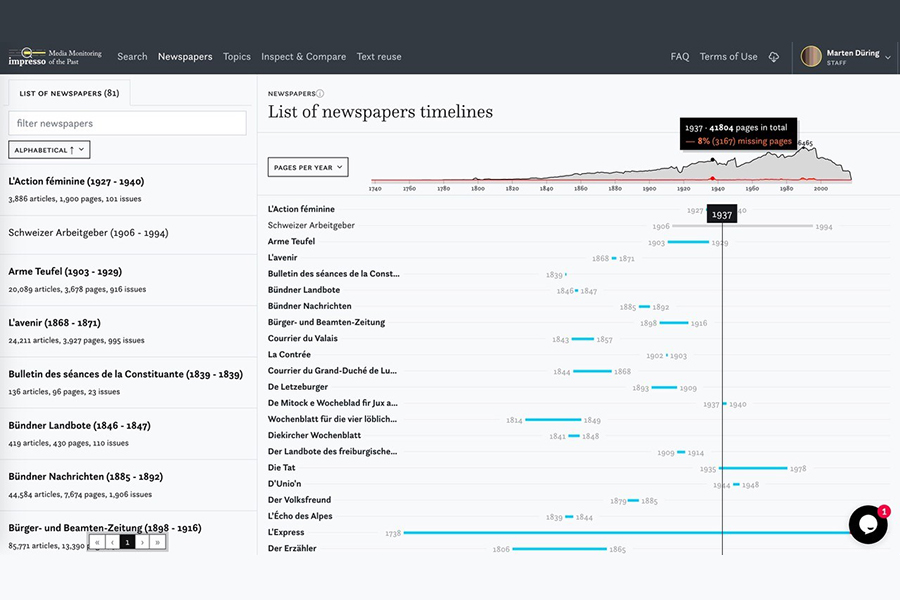

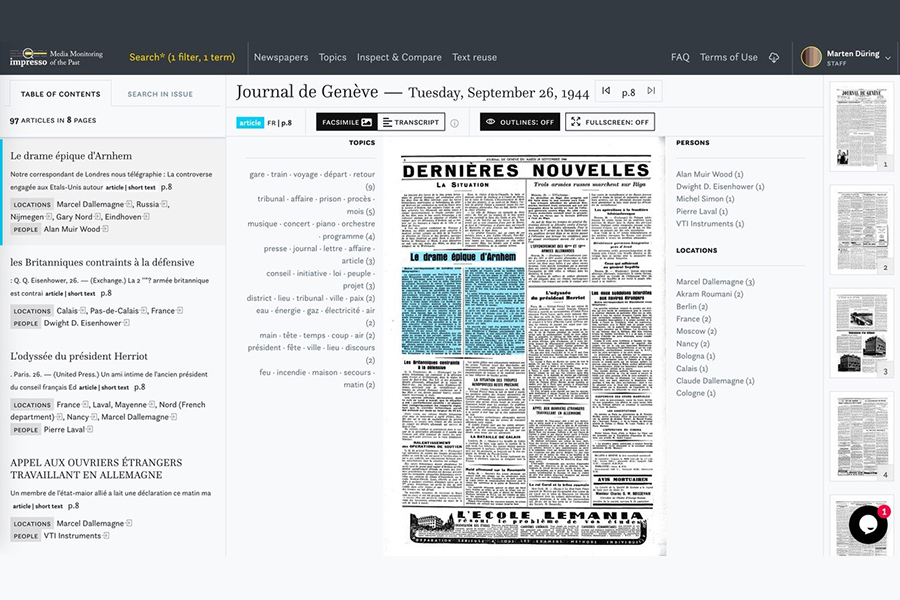

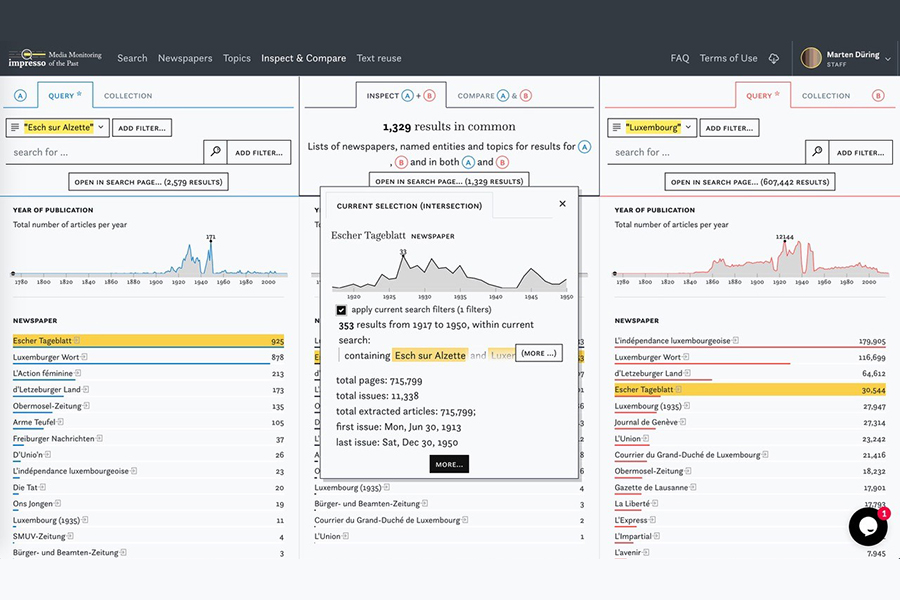
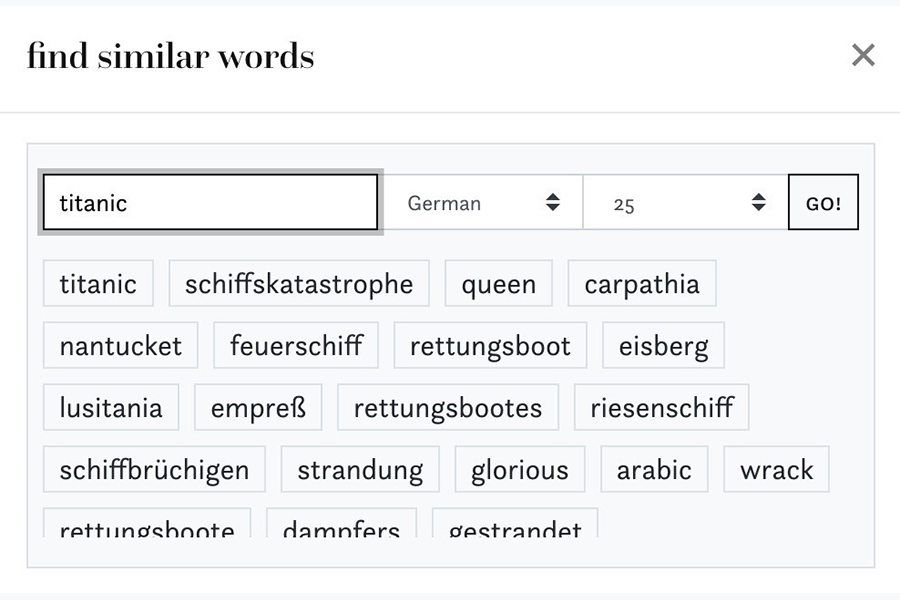
The impresso pipeline includes, for example, word embeddings to retrieve frequent OCR mistakes, synonyms, word neighbours or spelling variations; search facets based on pre-existing metadata (e.g. title, country of publication) and newly extracted semantic annotations (e.g. topic models, named entities). Each of the NLP enrichments serves as the basis for new interactions with the digitised newspaper collection, via the interface that the Luxembourg branch of the team is building.
Since the beginning, the impresso project has seen five releases of the interface and underlying newspaper data:
The impresso interface was designed with the overall ambition to facilitate content discovery based on text mining and the critical assessment of the underlying corpus, in line with best practices in historical research. The interface allows iterative exploration workflows.
Indeed, the growing digitisation and online publication of millions of pages of newspapers does not equate with easier access for research purposes. The challenge taken up by the project consists in not merely applying NLP to historical digitised sources but also finding a balance that enables rich, in-depth, precise and relevant interactions with the digitised materials. The interface was designed to foster iterative query-building, meaning that a given query can be altered within a component by either broadening or restricting its scope. In practice, this gives users the ability to e.g. expand their search result lists by complementing the search terms with historical spelling variations, filter by interrelated topics, exclude irrelevant entities, and adjust time filters based on n-gram frequencies.
The introduction of new tools also needs to be accompanied by teaching materials and constant exchanges with the researchers destined to use them. To that end, the impresso project has produced a range of training materials for researchers (PARTHENOS) and students (RANKE2).
The year 2019 witnessed a boost in community-building efforts, with the continuation of the impresso talk series (eight presentations by practitioners of digitised newspapers), one community call dedicated to topic modelling, a presentation at the DH conference in Utrecht, and active participation in the network of German-speaking researchers working with digitised newspapers. The momentum of digitised newspapers was visible in Utrecht, which may also explain the success of the call for papers for a conference dedicated to the epistemological questions they raise (60 submissions to Eldorado). Keeping in touch with the need of researchers led the team to develop an analysis of interfaces dedicated to digitised newspapers that was presented at the IFLA 2019 in Athens.
Project homepage: https://impresso-project.ch
Access to the interface: https://impresso-project.ch/app/
Digital History Advanced Research Projects Accelerator
The Digital History Advanced Research Projects Accelerator (DHARPA) adds a new dimension to the research activities of the C²DH by focusing on R&D. → read more
Confronting the Digital Turn in the Humanities
As a result of the “digital turn”, the humanities are currently in a process of rapid transformation, with consequences that reach far beyond the confines of academia. → read more
Technological Pasts in the Digital Age
9th Tensions of Europe Conference The 9th Tensions of Europe conference was organised by the C²DH and held at the University of Luxembourg from 27 to 30 June 2019 https://www.tensionsofeurope.eu. → read more
Digital History as Trading Zones
Under the term “digital history”, historians have experimented with tools, concepts and methods from other disciplines, mostly computer science and computational linguistics, to benefit the historical discipline. → read more
Women on the march from 1919 to 2019 in Luxembourg
Forum Z or the interaction of the C²DH with the public The aim of the Forum Z (Z for Zeitgeschichte or contemporary history) series is to promote a critical, open debate on topical issues in contemporary Luxembourgish and European history. The hundredth anniversary of women’s right to vote in Luxembourg was an anniversary not to be missed! While the National Museum of History and Art (MNHA) marked the anniversary with a major exhibition on universal suffrage, this Forum Z used it as a starting point for a broader reflection on what has changed for women over the past century. → read more