








A global outlook
The C²DH is committed to outreach as a means of engaging the public and promoting a better understanding of history in the digital age. Outreach activities include organising conferences, workshops and public lectures as well as publishing virtual exhibitions, open access books, podcasts and other digital outputs.
Virtual exhibitions and online projects
The C²DH’s virtual exhibitions offer an immersive experience of the past by providing unique insights into historical topics like the world wars in Luxembourg, the complex past of the industrial Minett region or the history of East Belgium. These exhibitions reflect the latest advances in digital technologies, breaking the mould of traditional storytelling with virtual curated narratives presented in a non-linear manner and including multimedia content and interactive features to provide an informative and entertaining experience.
-

Gilbert Trausch – A life dedicated to history (1931-2018)
This online exhibition about Gilbert Trausch – an emblematic figure of Luxembourg historiography – provides a unique view into a historian’s work before and at the onset of computerised support.
-

WW2.lu. Luxemb(o)urg in the Second World War
WW2.lu is a multilingual online exhibition which presents the history of Luxembourg during the Second World War, taking account of recent historical research.
-

The History of the National Miners’ Monument in Kayl
Between 1860 and 1980, mining operations in the Grand Duchy claimed the lives of approximately 1,500 mine workers. In their honour, the municipality of Kayl erected a monument in the mid-1950s, just opposite the “Léiffrächen“. Discover the history and statistics on this website.
-

WARLUX
The Warlux project website focuses on wartime experiences of young Luxembourgish men who served in the German labour service and armed forces during World War II. The website’s database includes a large collection of digitised war letters.
-

Gazengel
Meet Gazengel, a PhD student imagined by Alinéor Gandanger, herself a doctoral candidate at the universities of Caen and Luxembourg. Gazengel takes you behind the scenes of a young researcher and will explore the different facets of her scientific and creative adventures.
-

Framing Luxembourg
With “Framing Luxembourg” Statec and the Centre for Contemporary and Digital History tell “a history of Luxembourg in statistics as well as a history of statistics in Luxembourg”.
-

Minett Stories
The virtual exhibition Minett Stories deals with the history and identity of Minett, the industrial region in southern Luxembourg, in 22 chapters.
-

Memorial of the Shoah Luxembourg
This Memorial is bridging stories and memories of victims and survivors of the Shoah.
-

Popkult60 online exhibition
The digital exhibition of the Popkult60 research project on the transnational history of 1960s popular culture explores the rich cultural production of the 1960s and the connections between European countries.
-

175 years of POST Luxembourg
A virtual immersion in the world of stamps, mail, telecommunications, satellites … and of the men and women serving Luxembourg citizens since 1842.
-
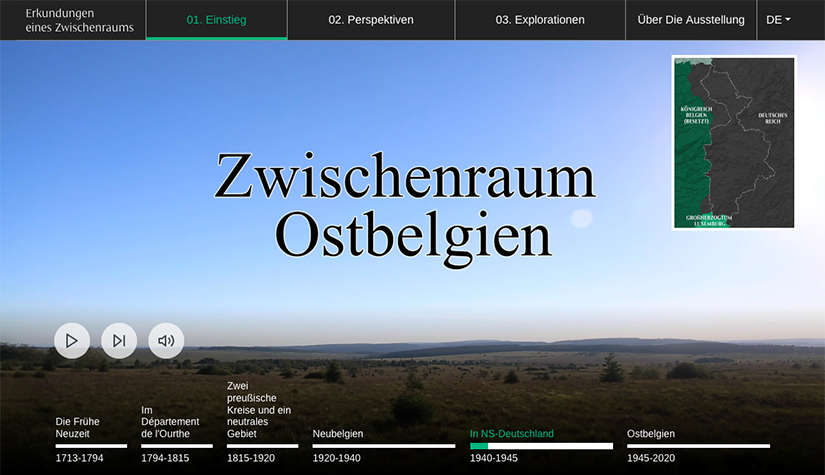
East Belgium 1920-2020. Prospecting an In-Between
East Belgium 1920-2020 is a virtual exhibition about the History of the region Eupen-Malmedy-Sankt Vith since the change of nationality in 1920.
-

Schumann’s Eck
Interactive documentary produced by students on the Bachelor course in Contemporary History of Luxembourg, in collaboration with the National Museum of Military History in Diekirch, on the occasion of the 75th anniversary of the Battle of the Bulge.
-

BGL: L’histoire d’un siècle
The virtual exhibition was developed by the C²DH to mark the BGL BNP Paribas’ centenary year. The retrospective covers the history of the bank from 1919 to today.
-

Éischte Weltkrich : Remembering the Great War in Luxembourg
The virtual exhibition developed by the C²DH retraces key aspects of the history and memory of the First World War in Luxembourg.
-

CVCE.eu by uni.lu
A collection of thematic ePublications on the European integration process from 1945 to 2014. An analysis of a range of subjects based on an extensive and contextualised selection of more than 25.000 relevant and enriched multimedia, multisource and multilingual documentary resources.
-

Covidmemory
With the online platform covidmemory.lu the C²DH wants to offer all people living or working in Luxembourg the opportunity to share their experiences of the Covid pandemic and preserve them for future generations. Anyone can upload photos, videos or texts to this open and free web-based platform, allowing us to document how the pandemic has changed our lives.
-

A Colônia Luxemburguesa
This transmedia documentary takes us to the core of the so-called Colônia Luxemburguesa and invites us to discover together a century of common industrial, cultural and social heritage.
Journal of Digital History
As an international, academic, peer-reviewed and open-access journal, the Journal of Digital History (JDH) will set new standards in history publishing based on the principle of multi-layered articles.
The journal aims to become the central hub of critical debate and discussion in the field of Digital History by offering an innovative publication platform, promoting a new form of data-driven scholarship and of transmedia storytelling in the historical sciences.
Innovating & Sharing History podcast

Ever wanted to explore contemporary and digital history in new and exciting ways? “Innovating and sharing history” is the C²DH podcast that introduces you into playful experimentation with cutting-edge digital methods and tools for studying, interpretating, narrating and publishing contemporary history. In each episode, historians, data scientists, web developers and students will introduce you into the challenges of contemporary, public offering fresh perspectives and innovative approaches to sharing the past.
Book series with De Gruyter Oldenbourg
-

Public History from European Perspectives
With this book series, the C2DH wants to serve as a platform for public history, exploring its potential as an interdisciplinary field and a means of fostering and reflecting upon public engagement, dissemination and participatory practices in areas such as heritage-making, modes of display, and historical storytelling.
-

Transnational history of Luxembourg
The book series, Transnational History of Luxembourg, offers a platform for studies about Luxembourg in a European perspective. The book series places particular emphasis on the analysis of the political, economic, social and cultural history of Luxembourg from 19th and 21st century. The aim is to produce new knowledge about the transnational history of Luxembourg by studying phenomena and processes that have profoundly affected the country and whose comparative value exceeds the national perspective. The series is edited by Benoît Majerus and Denis Scuto.
-

Studies in Digital History and Hermeneutics
The series Digital History and Hermeneutics offers a platform for cutting edge scholarship in the emerging field of digital history and hermeneutics. It aims at making a critical intervention in the field of digital humanities and introduces key debates and concepts of digital history to the historical community at large. The series is edited by Andreas Fickers, Valérie Schafer, Sean Takats, and Gerben Zaagsma.
Annual reports
Read more about the C²DH’s highlights and achievements over the years. All our annual reports are fully digital.